Asio, SSL, and scalability
16 Aug 2015Let's say you want to build an SSL server in C++. Transmitting data is going to be a major part of your application, so you need it to be fast and efficiently use system resources, especially processor cores.
You may have heard of Asio (possibly better known as Boost.Asio). Asio is a "cross-platform C++ library for network and low-level I/O programming that provides developers with a consistent asynchronous model". It's widely used and mature, and in the future may be a part of C++17 standard library. Note that this post is not a tutorial or an introduction to Asio, but rather a study on how scalable it is in our use case, why it scales poorly and how to improve it.
Benchmarking
Asio includes SSL support using OpenSSL library. I've created an example,
"naive" benchmark that sets up a server with a given number of
threads, creates a given number of connections and measures the time it takes
each of them to send M messages of size N. The code uses Asio 1.10.6, which
is the current stable version. Here's how I compile it on OS X:
$ clang++ -std=c++11 -O3 benchmark_naive.cpp -o benchmark_naive \
-Iasio-1.10.6/include/ -I/usr/local/opt/openssl/include/ \
-L/usr/local/opt/openssl/lib/ -lssl -lcrypto
And here are example benchmark results on my machine (that has 4 cores with Hyper-threading, adding up to 8 virtual cores):
$ # 1 thread, 1 connection, 1000 messages * 10 MB
$ ./benchmark_naive 1 1 1000 $((10 * 1024 * 1024))
10000 megabytes sent and received in 22.392 seconds. (446.588 MB/s)
$ # 8 threads, 4 connections, 250 messages * 10 MB
$ ./benchmark_naive 8 4 250 $((10 * 1024 * 1024))
10000 megabytes sent and received in 52.821 seconds. (189.319 MB/s)
Let's put all of my results into a chart:
As you can see, the chart shows an increase in bandwidth for two threads, which we would expect even for a single connection (as one endpoint has to encrypt, and other decrypt the data). After that point, the bandwidth rapidly falls off with the number of threads, reaching about 200 MB/s when used with multiple connections. Connections can potentially run in parallel, so the ideal chart would show a linear speedup with the number of threads, capping at the ratio of 2 threads/connection.
Summarizing the experiment, Asio with OpenSSL not only does not scale with the number of threads, it actually slows down considerably when the number of concurrent operations is high enough. This suggests a heavy lock congestion. Let's check our theory in a profiler:
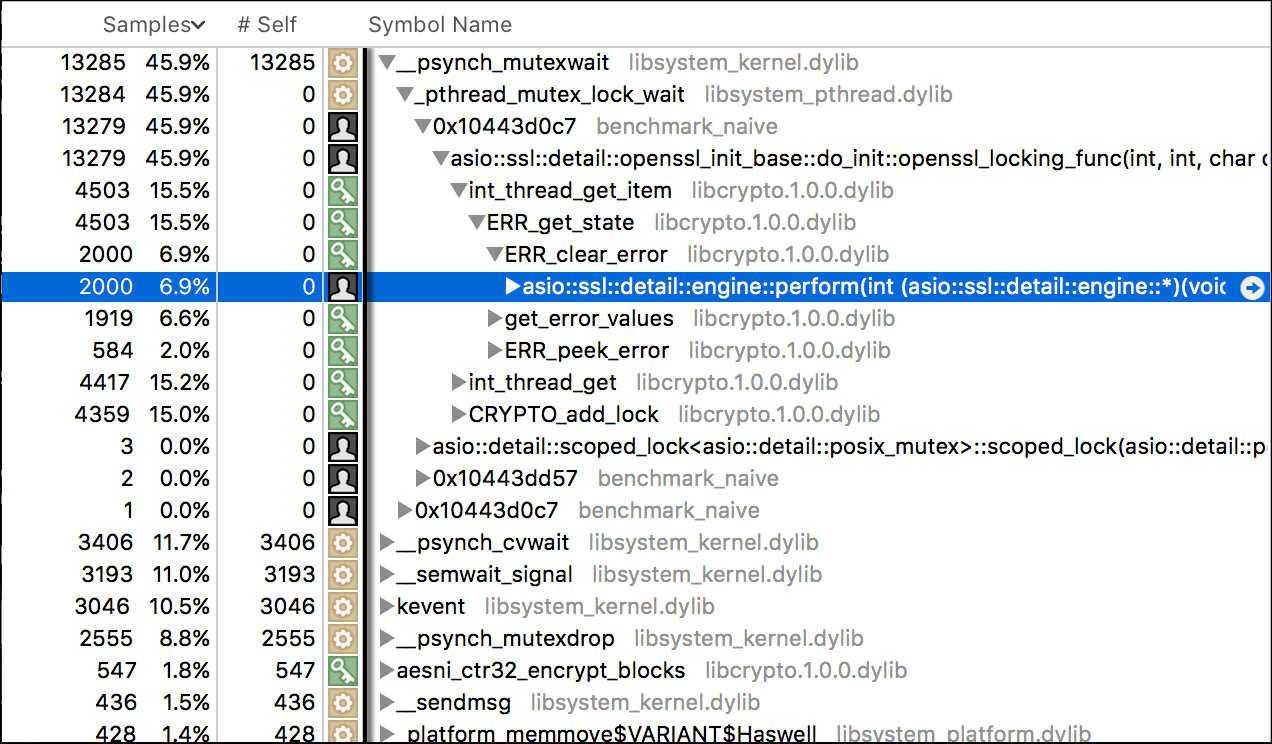
Most of the time of our application is spent waiting for locks, most of the
locking occurs in ERR_get_state OpenSSL function, and it can most often be
found in a call tree of asio::ssl::detail::engine::perform. A look at
engine::perform implementation in engine.ipp quickly shows us that...
everything is fine. Sure, you can maybe make a few small optimizations, but in
the larger picture OpenSSL is used correctly12. There's no error there
that would result in the lock congestion. We conclude that the bottleneck in
scalability lies in OpenSSL itself, more specifically in its error handling
functions. So what now?
Trying BoringSSL
After Heartbleed, a few OpenSSL forks like LibreSSL and BoringSSL have appeared with a vision to trim down, modernize and secure OpenSSL's code while remaining mostly source-compatible with the original. A quick look at LibreSSL's err.c file shows it's largely unchanged from the OpenSSL's version. But BoringSSL's err.c has obviously been reworked and now uses a thread-local storage instead of locking a global mutex for data access!
As I mentioned, BoringSSL is mostly source-compatible with OpenSSL. Unfortunately, there are a few changes to make before we can use it with Asio. There are open issues in Asio GitHub repository to integrate these changes into upstream, but even then compatibility with BoringSSL is currently a moving target as the code is still being cleaned up.
Let's compile the example with BoringSSL and run our benchmarks:
$ clang++ -std=c++11 -O3 benchmark_naive.cpp -o benchmark_naive \
-Iasio-1.10.6/include/ -Iboringssl/include/ \
-Lboringssl/build/ssl/ -Lboringssl/build/crypto/ \
-lssl -lcrypto
$ # 8 threads, 4 connections, 250 messages * 10 MB
$ ./benchmark_naive 8 4 250 $((10 * 1024 * 1024))
10000 megabytes sent and received in 11.591 seconds. (862.738 MB/s)
Well, that's much better. You may end reading here, knowing that as of this time OpenSSL's error handling causes it to scale poorly with the number of threads, while BoringSSL scales much better indeed. But there's still a fall-off in bandwidth when the number of threads increases, so let's try to answer that as well.
Cores, threads and io_services
If you want to find a bottleneck, profiling is usually the best answer:
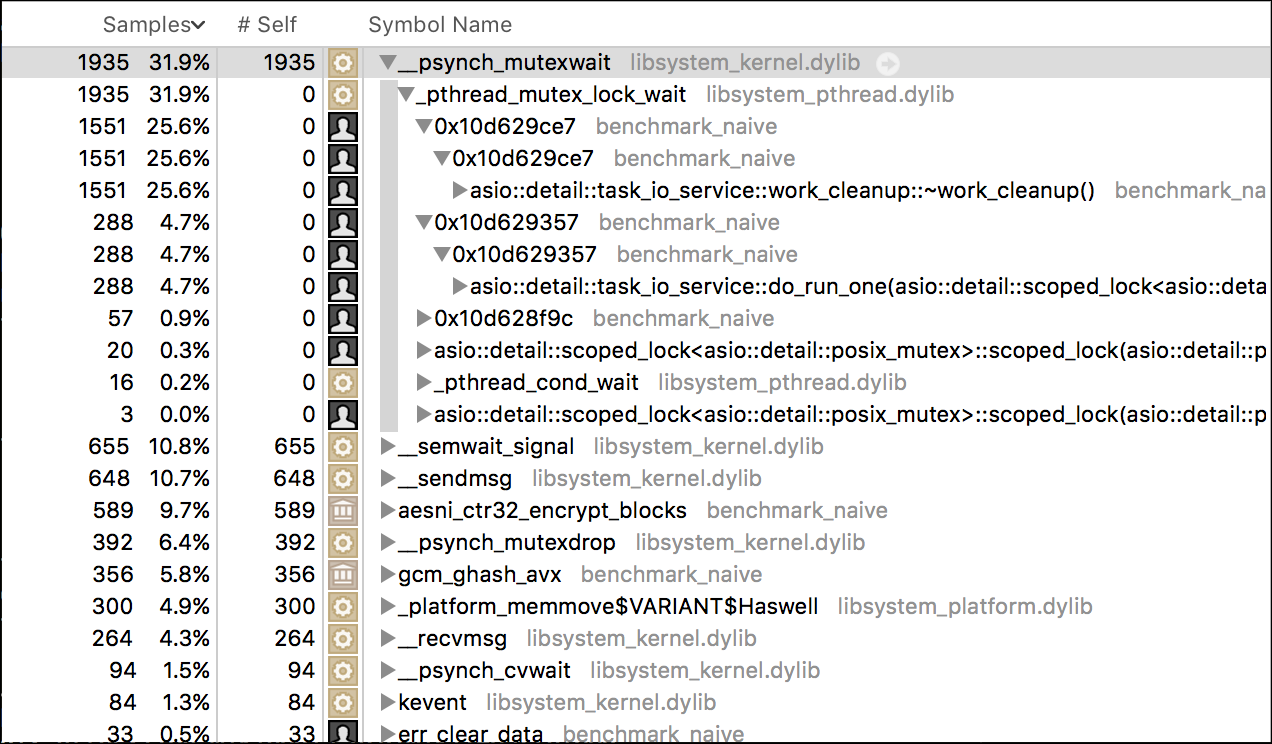
Looks like Asio's internal thread synchronization is the bottleneck this time.
There are two main approaches to get scalability in Asio: thread-per-core and
io_service-per-core. In the "naive" example I'm using the thread-per-core
approach as it always seemed more natural to me - we're basically creating a
threadpool that - if needed - can dedicate one or more threads to a single
connection, as opposed to io_service-per-core where each connection would be
served by at most one thread. But in the light of our profiling results I've
modified the example to use the second approach.
I've added a new class, IoServices, objects of which hold multiple
io_services. When we need an io_service - e.g. for a new client- or
server-side socket - we call ioServices.get() which will return one of the
stored io_service objects on a round-robin basis.
Let's put the results into a final chart. This time we'll just focus on 8
threads, 20 connections, and directly compare our different benchmark
applications. Note that I'm cheating here, if just a little bit:
io_service-per-core will perform better when there are multiple connections
per io_service, as it will result in a more balanced CPU load. Since we're
considering a server scenario, though, 20 connections is still a very low
number.
This still isn't the ideal chart (of course, due to threads' overhead no implementation can exist that would produce the ideal results), but it actually scales up with the number of used threads.
That's it for the post. Now that you know how to make Asio-based SSL server scale, you can go build a faster and safer applications.
Thanks for reading!
-
UPDATE 2015-08-17: While it's true that Asio uses OpenSSL API correctly, it's possible to write multi-threaded code that uses OpenSSL and which is not constrained by the error-handling bottleneck. Asio calls
ERR_clear_error()before each call toSSL_*()functions, as OpenSSL documentation states "The current thread's error queue must be empty before the TLS/SSL I/O operation is attempted". To avoid the bottleneck, instead of clearing the error queue before each operation, you have to make sure to clear the queue after an error has occurred. This is something that can be done in Asio code. ↩ -
UPDATE 2015-08-20: The update above turned out to be incorrect, as OpenSSL will still call locking functions internally. While the solution I described above will decrease lock contention, it doesn't completely remove the bottleneck. ↩