This is a status update for my Google Summer of Code 2013 project -
implementing advanced statistics importers for Amarok. Please read the
first post if you would like to know more about the project.
My GSoC project is done!
So many plugins!
Alright, not really. But, I already reached my hard goals and am well on the
way to finishing up on soft goals as written in my proposal: tests and two-way
synchronization. Reaching all the hard goals is something to celebrate!
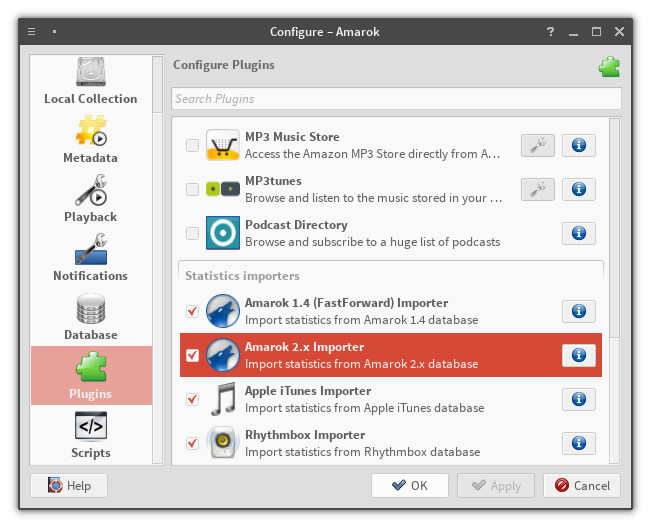
Amarok 2.x importer
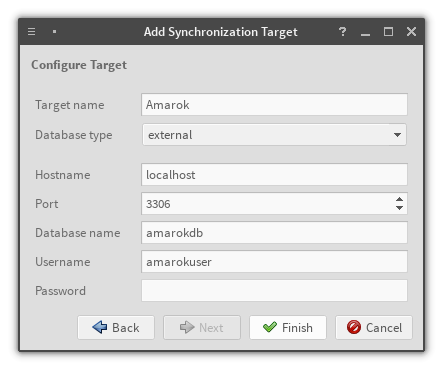
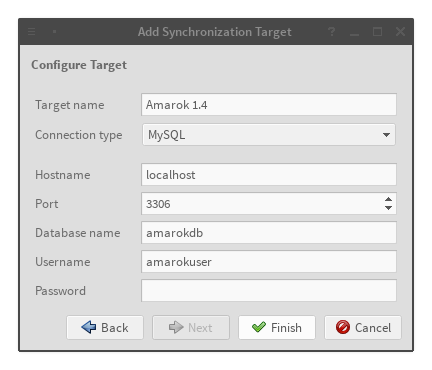
External connection config
The Amarok 2.x importer is up and running, and it supports both kinds of Amarok
database: external and embedded. The external one is pretty much your standard
SQL-based importer. The embedded one is much more fun.
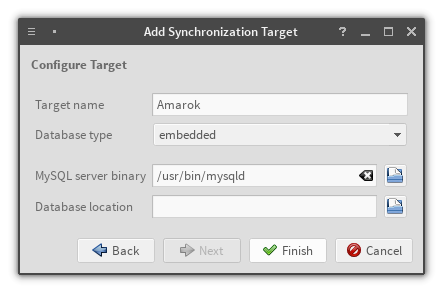
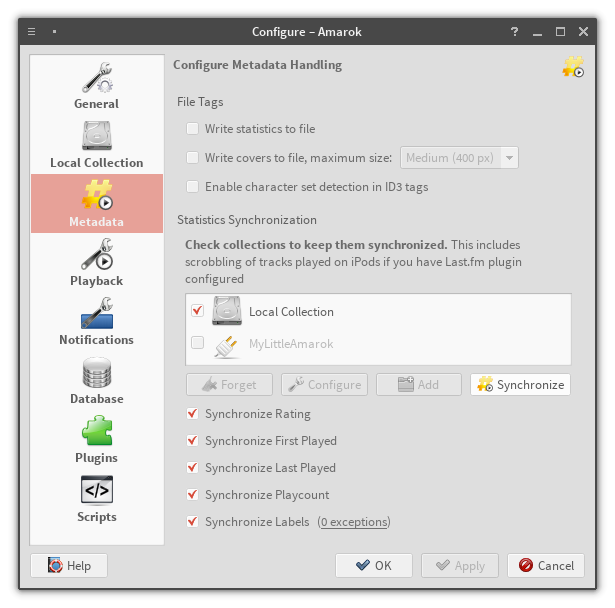
Embedded connection config
Obviously there's no daemon running when dealing with embedded Amarok database;
yet we have to start a MySQL server because data-mining its files is a
particularly bad idea. The most straightforward approach would be to simply run
an embedded MySQL server, but due to technical reasons we are limited to one
embedded server per process. This means that if current Amarok process stores
its collection in an embedded database - which is the default - we're quite out
of luck.
The solution I opted for is not perfect, but better than any other I could come
up with: start a server as a sub-process. The child is fed delicious arguments,
making it suitable to run in a multi-server environment, and under typical
desktop user's privileges. We then connect to the server and treat it in the
same way as external one: that's exactly what it is. The code is written in a
way that starts the server on demand and shuts it down after a period of
inactivity. Neat.
There are several drawbacks to this approach, the most obvious one being that
mysqld binary has to be present on the system. A less obvious one, but which
proved to be most troublesome, is lack of answer to a simple question: has the
server started up yet? We can't poll the output for equivalent of "ready to
serve" message, as it can be written in any language... or can it? There may
be another way to determine if the server is fully started, but I haven't found
one yet. So for now, after mysqld process starts, it's given a small time window
to get ready.
The future
In addition to things outlined in previous posts, I've got a few small tasks on
my to-do list - just some overall edge-rounding and a little problem-solving.
The process-handling part of Amarok 2.x importer will also be receiving a bit
more love, and hopefully I'll find a better solution to the problem mentioned
above. I'll also be looking into implementing Banshee importer.
As always, you can check out my progress on my public Amarok clone. The branch
is named gsoc-importers.
This is a status update for my Google Summer of Code 2013 project -
implementing advanced statistics importers for Amarok. Please read the
first post if you would like to know more about the project.
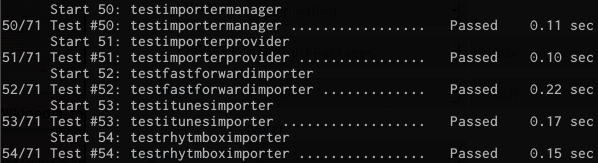
Well, this is going to be kind of a boring update. I implemented unit tests for
everything, Importers infrastructure (checking the documented properties,
testing interactions) and concrete importers alike. There were some minor design
changes but nothing interesting to talk about.
Who doesn't like to look at successful test results?
While making tests, I found and fixed a couple of small issues. So, nothing out
of ordinary, stuff simply works. I don't feel that the tests are necessarily
complete (and frankly, no tests are ever complete), but I'll still be working
on them and adding new ones when I see fit. It's still barely past the GSoC
midterm!
Oh, yeah, these tests I wrote at the beginning of the project? Not in the
current branch. These were acceptance tests for synchronization - with new
importers, it's the StatSyncing framework's responsibility and I realized that
this kind of testing specifically for importers has no sense. So, these tests
may yet see a come-back, in one form or another, but not as a part of Importers'
test suite - rather as more generic StatSyncing framework tests. It's a low
priority thing, though.
As always, you can check out my progress on my public Amarok clone. The branch
is named gsoc-importers.
Thanks for reading! Coming up next week - Amarok 2.x synchronization!
This is a status update for my Google Summer of Code 2013 project -
implementing advanced statistics importers for Amarok. Please read the
first post if you would like to know more about the project.
This week, I was meant to implement iTunes importer, bringing the total of
created importers to two.
So, as you can see, I kind of overshot my goal here.
What happened is, importers are now really easy and fast to implement. The only
really piece of programming required is to retrieve track data from whatever
source (in case of both iTunes and Rhythmbox the source is an xml file), and all
the rest is just filling the blanks.
As is visible on the screenshots, the icon used for iTunes is a generic double
eight note used elsewhere in Amarok as well - it will probably stay that way.
The fact is, Apple does not grant a blanket license for usage of their logos,
and different countries have different notions of what consists of "fair use" of
such an icon. So there's that.
I also managed to implement a prototype (i.e. it's almost done) ID3v2 importer,
reading POPM (Popularimeter) frame for statistics and otherwise acting as a
wrapper for existing collection's track. I'm conflicted about its usefulness,
though, as Amarok already reads POPM on collection rescan provided that
corresponding FMPS tags are not set - if they are, they have precedence.
Besides initial importing, which should be doable by simply removing FMPS tags
and doing a full rescan, there's also question of updating these statistics, but
I've yet to find a prominent media player using POPM as a primary way of storing
ratings and playcounts. And for a good reason - to begin with, there's no
standard as to what different ratings mean (the values range from 1 to 255), and
POPM is an ID3v2 feature only - not that useful from media player's point of
view.
So, the future is now. Some more importer targets can definitely be expected
(Clementine? Foobar2000? I guess I'm taking requests!). Aside from that, I'm
still not done yet. Here's a short, by no means comprehensive list of what I
have yet to address:
code deduplication: right now declarations for importers' classes alone
can easily be longer than actual logic,
Amarok 2.x importer,
robustness, error handling: if anything, all plausible errors should cause
a warning in the terminal (and definitely nothing should break),
tests: this can take some time to adapt to the new framework,
two-way synchronization: this may very well introduce its own set of
problems, with synchronization and whatnot.
As always, you can check out my progress on my public Amarok clone. The branch
is named gsoc-importers.
This is a status update for my Google Summer of Code 2013 project -
implementing advanced statistics importers for Amarok. Please read the
first post if you would like to know more about the project.
I'm happy to report that every component of the Importers infrastructure is now
working. There were no major design changes from what I described in my last
status update. The most significant minor-ish ones are:
provider creation and configuration dialogs management was moved from
StatSyncing::Controller to the GUI (but the Controller is still tasked
with instantiating the dialog),
ImporterFactory was renamed to ImporterManager to better reflect its
responsibilities.
Otherwise, I implemented what remained to be implemented, squashed some small
bugs and added some polish. What I like to call "Importers framework" (but what
is probably too monumental of a name) is ready for service, although it will be
polished and improved still throughout the summer.
8076 words
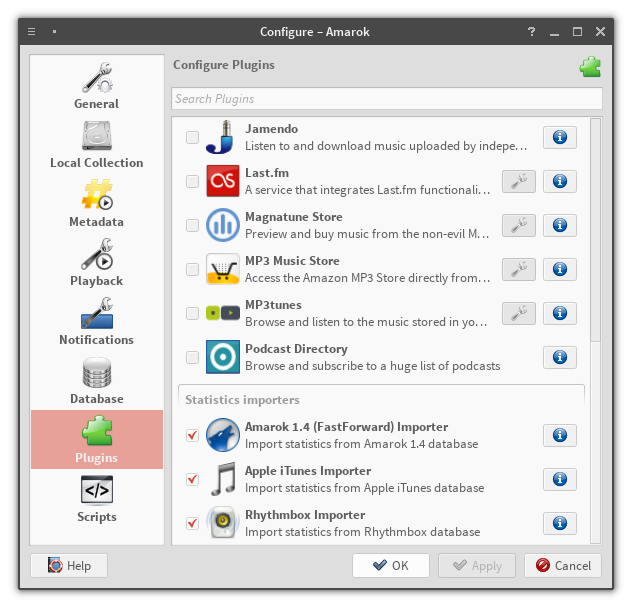
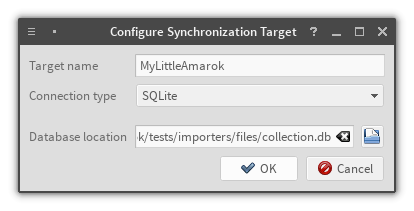
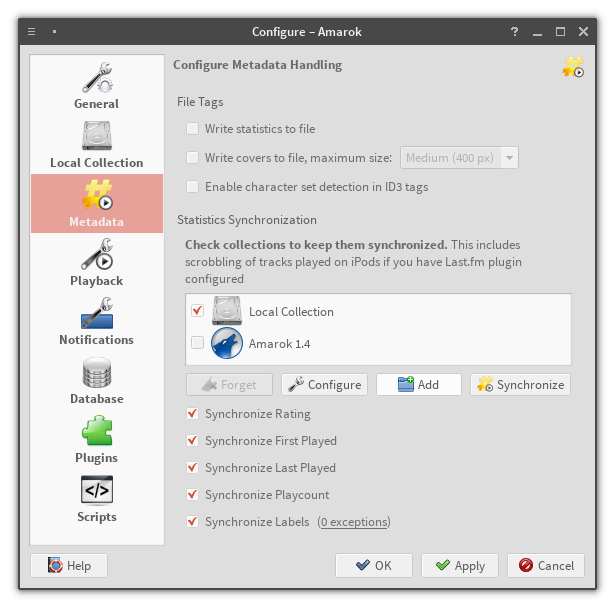
One plugin now, three left to goThe plugin is disabled – related providers are disconnected. Note that the "Add" button is grayed out
The plugin is now enabled. The "Add" button is enabled as well, and we can configure selected providerProvider creation dialog – configure the new provider
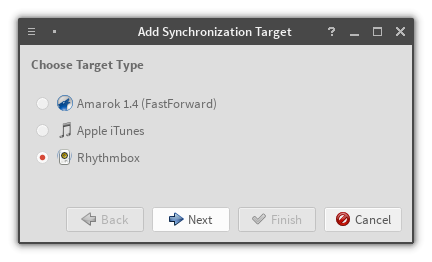
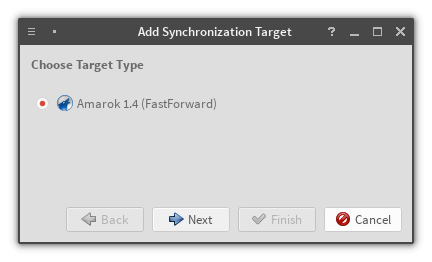
The provider configuration dialogProvider creation dialog – choose provider type
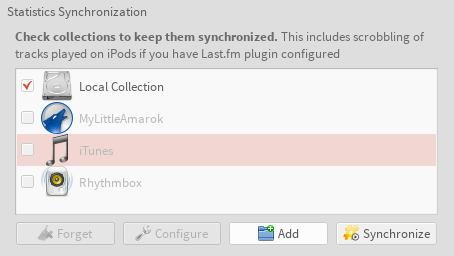
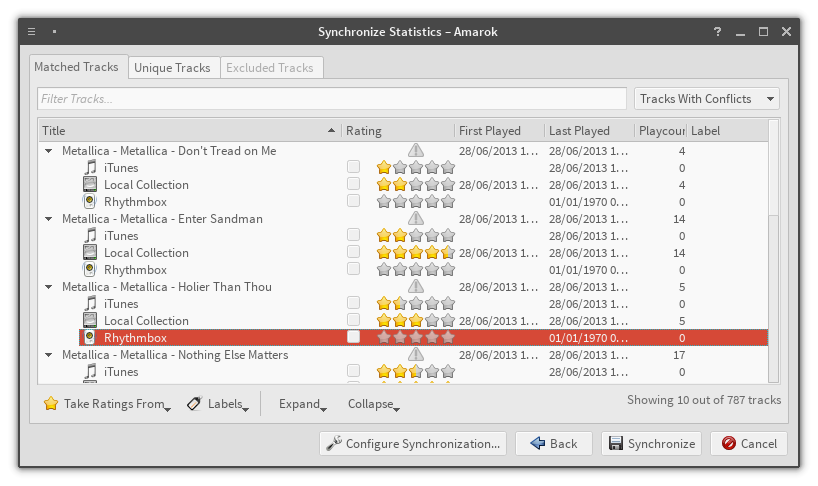
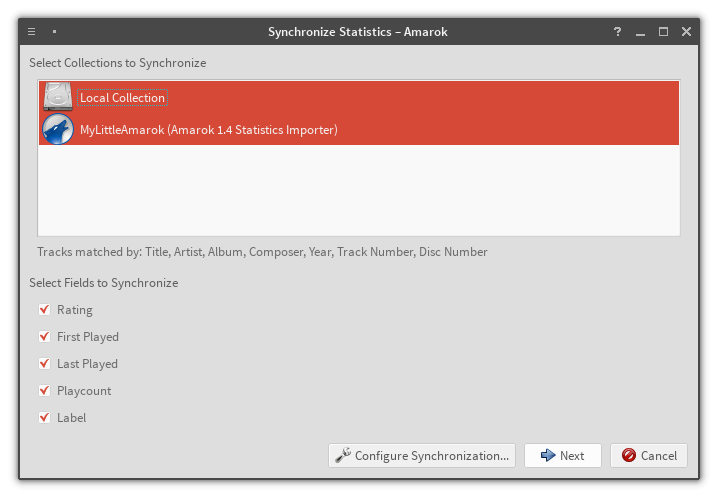
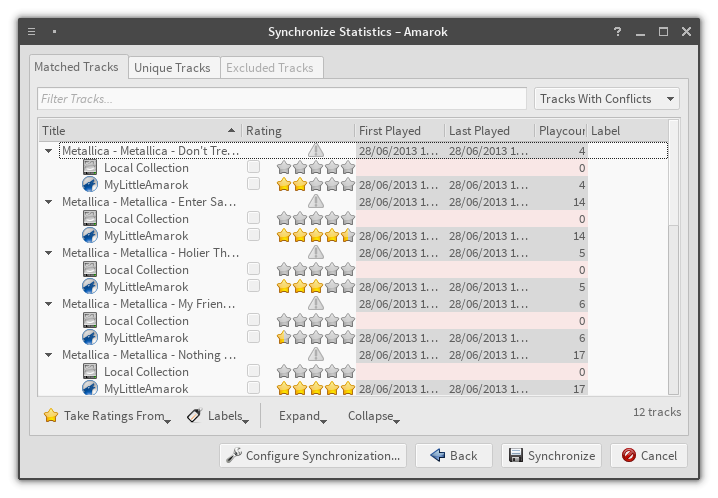
StatSyncing Synchronization dialog, choose providers to synchronizeStatSyncing Synchronization dialog – it works! Disclaimer: song ratings are test values
The future
This week I'm going to start and finish implementing iTunes importer. After that
I'm going to spend some time on tests, repurposing them for the new Importers
framework. If most things go well, everything that I have planned should be
ready for the GSoC Midterm Evaluation, along with some things I haven't (i.e.
the "framework").
After that, well, I don't know yet. I will get a taste of implementing a
concrete importer this week, and will see how much work it requires right now.
Depending on that, more importing targets than just Amarok 2.x and Rhythmbox may
be expected from the second half on my project.
As always, you can check out my progress on my public Amarok clone. The branch
is named gsoc-importers.
This is a status update for my Google Summer of Code 2013 project -
implementing advanced statistics importers for Amarok. Please read the
first post if you would like to know more about the project.
Let me clear some things out first. Scheduled: "Reimplementing FastForward
importer. At the end of the week I expect to have a functional importer,
possibly with some quirks to iron out. Implementing unit tests to assert
correctness." Done: I could argue the former; the Amarok 1.4 importer does
work, with some quirks to iron out. The latter? Tests are untouched.
Yet this was by far the most intensive week of coding so far, and the task I
focused on is the hardest part - the most important part - of the whole
project. First, to give some context, let's talk about how I design programming
frameworks.
How do I do it
I'm not much of a fan of the waterfall model. All of its other shortcomings
aside, I need to see how things actually work together, what is the overall
feel of the system. Designing by gut feeling may seem strange, but I'm sure
that many programmers will know what I'm talking about here; sometimes a
particular mechanism just feels awkward, particular responsibility ill-placed,
method redundant. This "methodology" is probably described and named, somewhere.
It's something like "incremental development meets rapid prototyping."
I start with a very rough draft of the system, and implement it using empty
classes, stubs, etc. (I like when things compile.) Then I pick a component -
maybe a single class, maybe a small family - and flesh it out. During this
process, I invariably become aware of multiple problems with the sketch, so I
rework it to address them. Then I pick another component, and the process
repeats. On each iteration I end up with a better design, and it can be vastly
different from the previous one.
The moral here is: as not every component is done yet, the system that I wrote
may undergo major changes, and definitely will undergo minor-ish ones. So,
on to the actual design!
The actual design
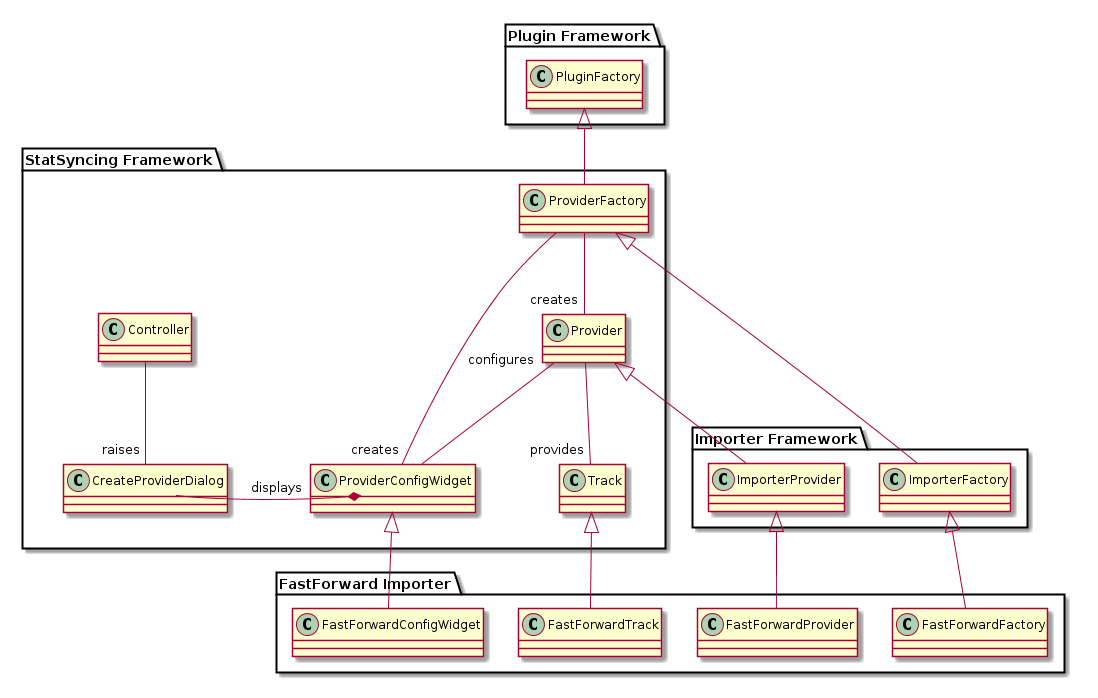
A picture is worth a thousand words, so here's a simple class diagram (please
note that only some associations are displayed; e.g. in reality Controller has
some kind of association with most of shown classes). I wrote this diagram
using PlantUML - give it a look!
Simple class diagram
First, importers are now plugins. That means that they need to be registered
with the plugin framework (using a semi-convenient macro), and they need to
provide a .desktop file containing some meta-information. On the flip side we
get automatic loading, which can be turned on and off at user's leisure.
Hey, it's a plugin! (Please disregard the description)
The plugin infrastructure takes care of instantiating and initializing
Plugins::PluginFactory class, which in case of importers is a subclass of
ImporterFactory, which in turn is a subclass of ProviderFactory. The
ImporterFactory and ImporterProvider classes are serving only as a common
base for importers, to reduce boilerplate code and duplication - all of the
relevant interface methods are specified in ProviderFactory.
The ProviderFactory contains, among others, methods returning: icon, name,
description, and configuration widget for that particular provider type. The
configuration widget is of type ProviderConfigWidget, which is an interface
with one method: config(), returning a QVariantMap populated with values set
by user. The returned QVariantMap is in turn used by another method of
ProviderFactory, createProvider( const QVariantMap &config ).
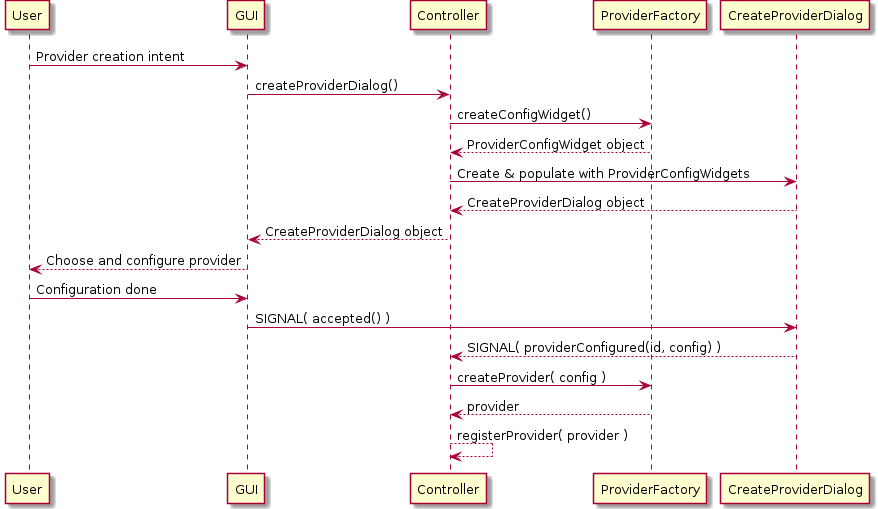
Provider creation sequence diagram
I've also extended StatSyncing::Provider with two methods:
ProviderConfigWidget *configWidget(), which returns a configuration widget for
this provider instance, if any; and bool isConfigurable(), which returns
true if provider is configurable. The reason for this is to enable
reconfiguration of importers, and putting it in a base class makes sense (in
future it could be used for Last.fm provider, for instance). The implementer of
StatSyncing::Provider is responsible for reconfiguring the provider instance
after the configuration is done. The question of how he will know that it's
done will be answered later, but reconfiguring can be done in much the same way
that initial configuration is done.
New buttons, and an added synchronization target
As I mentioned, ImporterProvider and ImporterFactory serve to reduce
boilerplate. They have some sane defaults which greatly reduce amount of code
needed to implement new providers, and I hope to reduce it yet further. For
starters, ImporterProvider by default delegates queries for description, icon,
configuration widget, to corresponding ImporterFactory. That means many
attributes need only be set in the ImporterFactory subclass, and not in the
Provider, and it will just work. While the reconfiguration part is not yet
programmed in, it will be done automatically by the framework; the same
ProviderConfigWidget will be used, prepopulated by ImporterFactory. The
factory will then create new provider using the modified config, and
transparently swap it with the old provider, immutable-style.
Current status
What works
FastForward Provider
registering plugins
provider creation dialog, complete with creating new provider
loading up configuration at startup
What doesn't
saving configuration at shutdown
reconfiguring provider
forgetting provider
dialogs being pretty - there's a reason for the lack of configuration dialogs'
screenshots
FastForward Provider - the tracks are found but displayed as unique, even
though the metadata seems identical
Plans for the future
Obviously my schedule is now a bit skewed, as by now I was supposed to finish up
FastForward Provider complete with tests, and start implementing iTunes
Provider. Right now the plan is to finish up the importers framework, so
everything that's needed is usable - doesn't have to be perfect yet. If things
will go as I anticipate, implementing iTunes Provider should be a breeze, and
creating every subsequent provider even easier.
As always, you can check out my progress on my public Amarok clone. The branch
is named gsoc-importers.